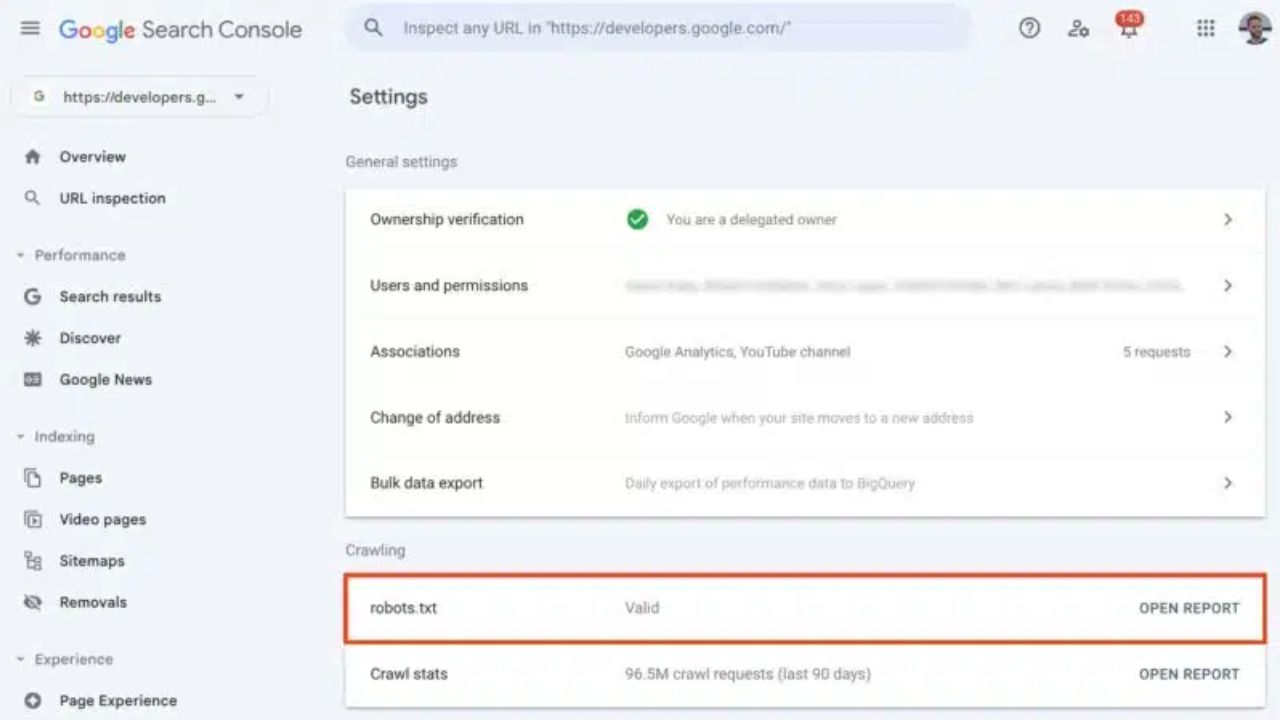
Robots.txt Report: A robots.txt file lets you tell search engines which pages to crawl and which ones to skip. Bots.txt files are found in the source files of many websites.
Google Search Console Introduces Comprehensive Robots.txt Report
Google Search Console now has a new robots.txt report. Google also made the page indexing report in the Search Console better by adding helpful details about robots.txt. Google has finally turned off the robots.txt tester.
Getting crawled and indexed might be hard for you. This report could help you figure out if the issue is with your robots.txt file.
This report in the Google Search Console is for the sites you are in charge of. Check it to make sure that robots.txt directives aren’t stopping Google from getting to your site.
This is the fresh robots.txt file. The new robots.txt report from Google tells you what the company knows about your file, including:
- Google’s list of the 20 largest hosts’ robots.txt files on your site
- When Google last crawled those files and brought up any problems or alerts.
- Google said that in an emergency, this report now gives you the chance to ask for a new crawl of a robots.txt file.
Open Google Search Console and go to “Settings.” There, you will find this report.
Google also made the page indexing report in the Search Console better by adding helpful details about robots.txt.
Google hasn’t using the robots.txt tester anymore since this new robots.txt report came out.
What is Google Bard and How to use it to get ahead of algorithm updates
What information will you find inside the robots.txt report?
You can see the following for each robots.txt file that Search Console has checked:
- File path: The full URL of the page where Google looked for a robots.txt file. Only URLs that have been marked as Fetched or Not Fetched in the last 30 days will show up in the report. Find out where the robots.txt files are.
- File fetch status: This is the status of the most recent request to fetch this file. It is possible for these values to be true:
- “Not Fetched” or “Not Found” (404): When this file was asked for, a 404 error message said that the file did not exist. If you posted a robots.txt file at the URL given but are still getting this error, check the URL to see if there are any problems with its availability. If a file has the status “Not found” (404) for 30 days, it will no longer show up in the report, but Google will still check it in the background. If you don’t have a robots.txt error, Google can still crawl all of your site’s URLs. For more information, see what Google does when there’s a robots.txt error.
- Not Fetched—Anything else: There was another problem when this file was requested. See the list of indexing problems.
- Fetched: The last crawl attempt brought back a robots.txt file successfully. The Issues column will show any problems that were found while reading the file. Google doesn’t use the lines that have problems; it only uses the ones that it can read.
- This field shows the date and time that Google last tried to crawl this URL.
- Size: In bytes, the size of the file that was fetched. If the last try to fetch failed, this will be empty.
Issues: The table counts how many parsing errors were in the file’s contents when it was last fetched. When there are errors, a rule can’t be used. A rule can still be used even if it has a warning. Find out what Google does when there is a problem with robots.txt. A robots.txt validator can help you fix problems with parsing.